Tuesday July 6, 2021
Ames Housing Progress Report
I was not highly productive yesterday but I did squeeze out some visualizations from the dataset.
As I said yesterday, I have split the dataset by feature into different domains. So I will try to get through one domain each day. The point is to get a very rudimentary understanding this week and not make any transformations to the data.
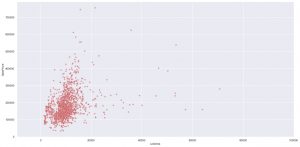
I wanted to see the relationship between plot size and price. The majority of the data comes in under 20,000 sq feet and $400,000 and there does not appearto be a linear relationship between price and lotsize.
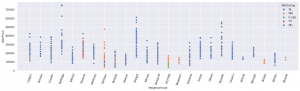
I also wanted to get an idea of which neighborhoods were more or less expensive to buy a house in. The second and third figure are too small to see clearly but the first shows the zoning of each neighborhood. RL is the residential low density zoning which forms the large part of the neighborhoods. It is also easy to which areas are residential medium density (RM). The FV is Foating Village, which is (possibly) a retirement community, is mostly in Somerset. There are very few Commercial or Residential High density zones.


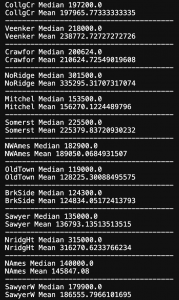
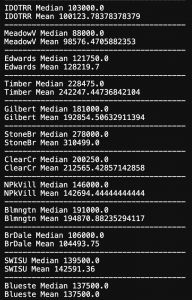
The three most affluent neighborhoos are North Ridge, North Ridge Heights, and Stone Brook. However, we must handle the outliers there. They would negatively affect our models. NRidgeHts has a higher median than regular NRidge. But the outliers raise the mean of NRidge considerably. Stone Brook and NRidgeHts have the same mean but NRidgeHts has a slightly greater median which edges it above Stone Brook in most expensive housing areas.
Follow-Ups: I could cross-compare the plotsize and neighborhoods to see what that gives us.
Podcast hour:
While I go on my morning walks I listen to different things. I was in the middle of A Tale of Two Cities (LibriVox has a great free dramatic recording) but I realized that I listening to a Data science podcast usually gets my head in the game for the day. Besides I am reading Dune in the evenings after I shut down for the day.
 So, my new podcast of choice is the Real Python Podcast….well…to be fair, it is an old podcast for me, however, they only release one episode a week and if I listen to one everyday then I quickly consume the interesting choices. Then, I want to wait for for a while for them to build up another batch that I can binge. The great thing is that their website gives thorough timestamps and links to sites in the conversation that it is easy to go and explore the topics.
So, my new podcast of choice is the Real Python Podcast….well…to be fair, it is an old podcast for me, however, they only release one episode a week and if I listen to one everyday then I quickly consume the interesting choices. Then, I want to wait for for a while for them to build up another batch that I can binge. The great thing is that their website gives thorough timestamps and links to sites in the conversation that it is easy to go and explore the topics.
Today’s choice was from last week, here. One small note of interest was an article about the future of data science between Excel and Python (spoiler: Python wins every time). But the accessibility of Excel means non-programmers are able to do data science type analysis. However, the downside is the frequent errors that pop up in Excel and the fact that it isn’t a secure database but people (not knowing better) use it like one which produces some significant problems. You should read about the mistake NASA made due to using Excel.
The highlight of the episode for me was a deep statistical analysis of lego prices. I think this one will be worth traversing later. Here is the link.